Introduction
GlusterFS is a distributed file system for huge data storage. Red Hat acquired it from Gluster Inc. GlusterFS is an open-source distributed file system that stores and manages massive volumes of data across multiple devices. It handles data-intensive workloads flexible, scalable, and robustly. It is very suitable for media streaming, archiving, and cloud storage. In this blog post, we will discuss the GlutsterFS architecture and components of GlusterFS as well as explore its various use cases.

GlusterFS Architecture
GlusterFS architecture is a scalable, distributed file system that can run on commodity hardware. It’s architecture is based on a modular design that enables for simple customization and deployment.
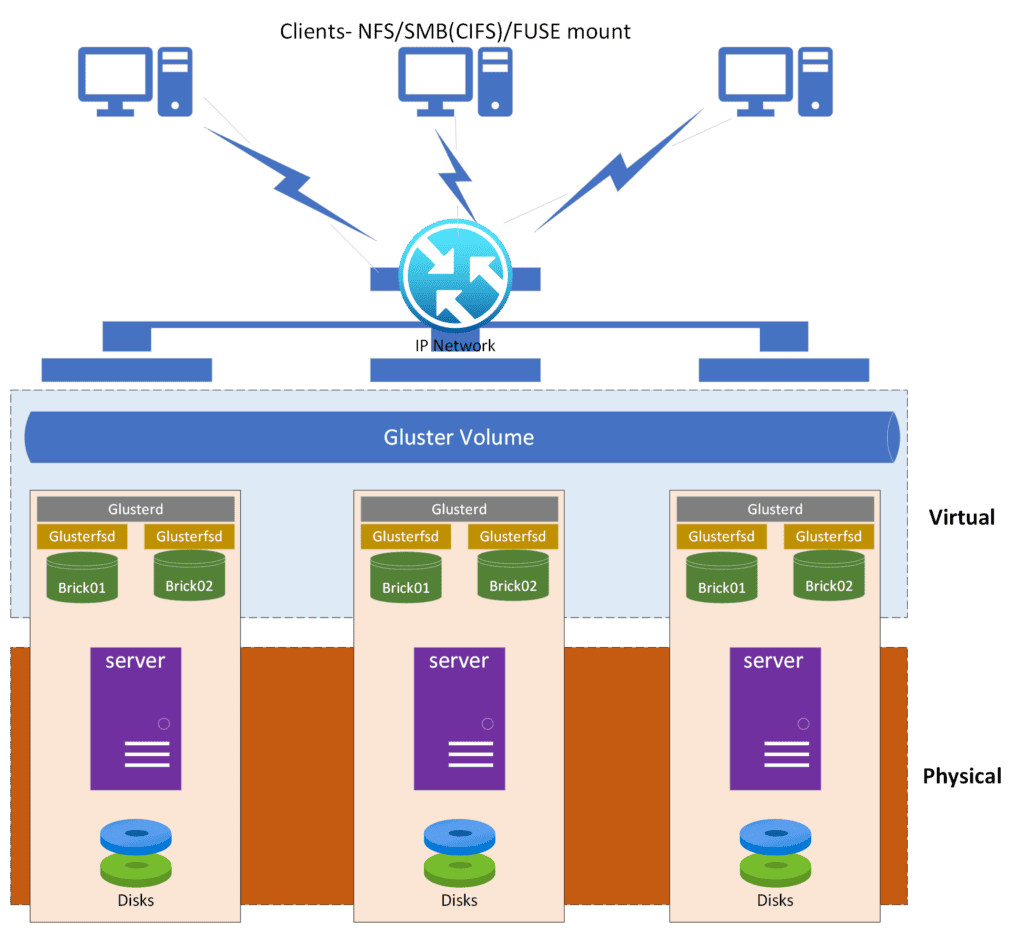
GlusterFS employs a client-server architecture in which clients access data stored on several servers. The smallest fundamental unit is termed as a “brick,” and it serves as storage for the file system. Clients access the file system via a mount point maintained by the GlusterFS client.
To manage file information and distribute files throughout the storage pool, GlusterFS employs a distributed hash table (DHT). The DHT provides a uniform naming scheme for files, regardless of their physical position in the storage pool. This means that a file is retrievable by its name regardless of whatever server it is stored on.
GlusterFS additionally employs a translator architecture to provide additional capabilities such as caching and encryption. Translators can be added to the file system to give additional functionality while not compromising the file system’s fundamental functioning. For better understanding, the details of each component are provided below.
Server Components
The GlusterFS component that stores data and metadata is the storage server. It is in charge of upholding data availability, ensuring data redundancy, and keeping data consistency. Depending on the needs of the application, there are several possible configuration available to setup a storage server, such as distributed, replicated, and striped.
Data is replicated among several storage servers in a distributed mode, enabling excellent scalability and performance. Data redundancy and high availability are both provided by the replicated mode, which replicates the data across numerous storage servers. High performance is provided via striped mode, which stripes the data over numerous storage servers.
Glusterd
Glustred is the administration daemon that oversees the entire system. It offers a web-based graphical user interface and a command-line interface for system management. It oversees the cluster’s configuration and controls how the servers communicate with one another.
Gluster Server
A server is a system that provides storage for GlusterFS. Each server in a GlusterFS cluster stores one or more bricks which is logical smallest unit of GlusterFS.
GlusterFS Protocol
GlusterFS uses the GlusterFS protocol as a network protocol for communication between its servers and clients. The protocol offers a way to access the data kept in the GlusterFS volumes and is based on the Remote Procedure Call (RPC) mechanism.
Brick
Bricks are the smallest unit of storage that may be used with GlusterFS. It can either be a directory or a block device, but either way, it is anything that is exported from one server to other servers in the cluster. Each brick comes from a distinct server and is accessible via a network.
Volume
In GlusterFS, a big storage space volume is basically a collection of bricks and one volume can spans across numerous servers and there are variety of ways to setup a volume to give varying degrees of redundancy and data security. A volume is capable of being segmented into smaller sub-volumes, each of which can have its own unique set of bricks.
Cluster
A GlusterFS cluster is a collection of computers that operate in concert to offer a distributed file system to users. GlusterFS cluster is capable of providing both High availability and fault tolerance, which can span different data centres. Using the GlusterFS protocol, the servers that make up a GlusterFS cluster are able to communicate with one another across the network.
Translator
Translators perform replication, caching, or encryption. Translator stacks provide application customization. The translator converts client requests into storage server-friendly commands. No matter the storage server method, the translator must give the client access to the data. The translator can cache, encrypt, and compress. It also allows administrators to control data access.
- Protocol translators: These translators provide access to the GlusterFS volume using various protocols, such as NFS, SMB, and FUSE.
- Storage translators: These translators provide features such as data replication, striping, and snapshot management.
- Performance translators: These translators optimize performance by providing caching and load balancing.
Client Components
The client is the component that accesses and manipulates data stored in the storage server. It communicates with the storage server using GlusterFS protocols, which allows it to perform operations such as read, write, and delete on the data stored in the storage server.
Client can access data from single storage server or in a distributed storage cluster. It is also compatible with different operating systems clients to access data and integrated with different applications to provide shared storage.
GlusterFS Clients
The GlusterFS client is a module that is installed on the client computer and is responsible for providing access to the data that is kept in the GlusterFS volumes. Also, regular file system clients like NFS, SMB, FUSE and Swift clients can access GlusterFS virtual file system.
- FUSE Clients: File system in User-space, or FUSE for short, is a software interface that enables user-space programs to communicate with the file system. It is employed on the client system in order to mount the GlusterFS volume.
- Native Clients: The native client is a library that offers an application programming interface (API) for accessing the file system. Applications are able to make use of it to gain direct access to the file system.
- NFS Clients: Network File System(NFS), is a protocol that enables file sharing between computers on the same network. It allows clients located in different locations to access the GlusterFS volume.
- Samba/CIFS Clients: These are the clients that access the GlusterFS volume using the Samba/CIFS (Common Internet File System) protocol. Samba/CIFS clients are available for Windows, Linux, and Unix operating systems.
- Object Storage Clients: These are the clients that access the GlusterFS volume as an object storage system using protocols such as S3 and Swift. Object storage clients are available for Linux, Unix, and Windows operating systems.
GlusterFS Usage
Streaming media, data analytics, and cloud storage are just some of the many uses for GlusterFS. Below are some of the typical use cases where GlusterFS thrives:
Virtual Machines’ Data-store
GlusterFS can provide as storage for virtual machine instances on virtual environments such as, VMware, Hyper-V, KVM etc. For purposes of backup, migration, and disaster recovery, it offers scalable and resilient storage for virtual computers.
Media Streaming Storage
Streaming media, such video or music, is a possible use case for GlusterFS. High-performance media file storage that supports concurrent client access is provided.
Cloud Storage
As a storage back-end for cloud applications, GlusterFS is an option to consider. Cloud apps can make use of its scalable and reliable storage to store and back up their data. GlusterFS, when deployed on a cluster of virtual computers, allows businesses to set up a highly available storage infrastructure for cloud-based programs.
Big Data Analytics
For big data analytics using frameworks like Apache Hadoop and Apache Spark, GlusterFS can serve as a storage back-end. Organizations may boost the efficiency and scalability of their analytics workflows by storing and managing massive data sets with GlusterFS.
Content Delivery Network (CDN)
Storage and distribution of static media files over a cluster of servers is one of GlusterFS primary usage. Organizations can enhance the efficiency and reliability of their content delivery networks by adopting GlusterFS for data storage and distribution.
Archival Storage
Protect and restore with GlusterFS by making copies of your most important files and programs as archive for long retention of period. In the case of a disaster, businesses can rest easy knowing that their data is secure and easily recoverable thanks to data replication across many servers.
Backup and Recovery
GlusterFS is also a great candidate for use as storage library to create backups of critical data and applications. By replicating data across multiple servers, organizations can ensure that their data is safe and recoverable in the event of a disaster.
Conclusion
In terms of scalability, stability, and performance, GlusterFS is an excellent distributed file system. In this post we explore GlusterFS architecture and components briefly. Because of its client-server design and distributed hash table, it can store vast amounts of information and make files accessible from anywhere in the world. Addition of new feature does not effect the file system’s essential functioning, thanks to its translator design. GlusterFS has several possible uses, such as video streaming, data archiving, and cloud storage. Users can build massive storage infrastructures with GlusterFS since it is a distributed, scalable, and highly available file system. It’s open source and free, so you can use it to make anything from cloud storage to VMware to a centralized file repository.